

Therefore, as the verification gives more confidence in the logic of the program itself, it becomes more important to worry about errors in the environment surrounding the program. CertiK carried out a research project about how to improve a particularly important part of the execution environment, namely the compiler. We produced a formally verified compiler for smart contracts, which we call DeepSEA.
A compiler takes contract source code written in a high level language (Solidity, Rust, Vyper, ...) and translates it into bytecode that can be executed on a blockchain (EVM, WebAssembly, ...). It is one of the most complicated parts of the technology stack. For example, the Solidity compiler contains around a hundred thousand lines of code. By comparison, all the work to validate an Ethereum block (the "core" of go-ethereum) only requires fifty thousand, of which the EVM bytecode interpreter is seven thousand. It is hard to make such a complicated program completely correct, and indeed the Solidity compiler team discovers and announces several security bugs each year.
Mistakes in the compiler could cause a correctly written smart contract to be translated into bytecode with security vulnerabilities, which is particularly insidious because most security reviews focus on the source code of the program. You would need bad luck to stumble on a compiler bug in this way, and in practice such security errors are less common than simply incorrectly written contracts, but they still occur in practice: for example this August, Curve was hacked because the Vyper compiler had a bug in the code that allocates locks in storage, which broke the contract's protection against reentrancy attacks.
When performing formal verification, we should also be concerned about bugs in the verification tool. Just as a normal compiler translates Solidity source code into EVM bytecode, a verification tool translates Solidity into a model in a low-level verification language such as Boogie. If there is an error in either of these translators there could be a discrepancy between the model of a program and the actual execution of it, which could invalidate the formal verification guarantees.
DeepSEA aims to solve both these issues. It uses formal verification to avoid compiler bugs and it is directly integrated with the verification toolchain. This technology lays the foundations for end-to-end security in the Web3 world.
How to Write a Verified Compiler
Compilers are complicated, and for many decades they were considered a major challenge for formal verification. Starting in the 2010s, computer scientists developed methods to handle this problem, which we applied in this project. In short, the problem can be broken down into:
- Specifying what the compiler should do
- Writing the compiler itself, and
- Proving that it satisfies the specification
Specification involves writing a precise description of the programming language to be compiled, along with the target bytecode. The description says exactly what programs are valid and what they do when executed. In the DeepSEA project there are three languages involved. Rather than Solidity, programs are written in a rather minimalistic language which we call the DeepSEA surface language, and which was designed to interface well with the Coq proof assistant. The compiler first translates DeepSEA programs into an intermediate programming language which we call MiniC (which is more similar to Solidity and Vyper rather than the purely functional Coq language), and ultimately, MiniC can be compiled to either WebAssembly or EVM bytecode. For each of these languages there is a machine-readable specification defined inside the Coq proof assistant; we wrote semantics for the DeepSEA surface language and MiniC languages and re-used existing semantics for WebAssembly and EVM.
The compiler itself is written in Coq's built-in programming language (Gallina). Its tasks echo those of other compilers: allocating variables in storage, building a control flow graph, allocating temporaries via a live-variable analysis, transposing expressions into stack operations, amalgamating all methods into a singular program, performing peephole optimizations, and emitting bytecode instructions. One thing that is different about this compiler is that it is split into many granular "phases" (in our case 12 different steps). Dividing the compiler into small modules makes it easier to prove the correctness of each one, whereas if we did not intend to verify it we would probably combine them into larger functions.
Using the Compiler
The code of this compiler is published. Currently the compiler supports two targets: EVM bytecode, and Ethereum-flavored WebAssembly (eWASM). The latter is a proposed alternative to EVM which supports a similar set of system calls. The two parts of the backend reuse some of the same phases (e.g. the live-variable analysis), but then diverge into two different code paths. The compiler can compile the DeepSEA surface language, and the backend can also be used as a stand-alone library to compile the intermediate language "MiniC", so it can be used as a backend for other smart contract programming languages.
Verifying Compiler Correctness
After writing the compiler code, we prove the correctness of each compiler phase, and therefore of the compiler as a whole. For each phase, we write a definition of the programming languages it takes as input and output and their semantics. The verification engineer needs to invent and define a relation called match_states between the states of a program in the input language and the states of the corresponding compiled program.
For example, one of the compiler phases places local variables into the EVM stack. In the input language to that phase we assume that there is a set of variables which each have some current value (specified in a "temp_env"), and programs in the input language can read variables by name. In the output language there is no concept of named variables, but rather a stack which can be accessed by position. The strategy (same as the Solidity compiler) is that each compiled method will store its local variables at the bottom of the stack. So the most important part of the compilation relation for this phase is a definition saying that the the stack holds the list of values corresponding to a temp env:
Inductive match_temp_env: temp_env -> list (ident * type) -> stack_entries -> stack_entries -> Prop :=
| match_temp_env_intro: forall le temps s s_tail vals,
flattened_temp_env temps le = Some vals ->
stack_top s vals s_tail ->
match_temp_env le temps s s_tail.
This relation between stacks will hold before the execution of each line of code of a function body in the input language. Of course, the full relationship between input and output programs is more complicated, because we must talk about all the state of the program (memory, storage, program counter, etc). But because each phase does such a small amount of the work, all the rest of the program state can be exactly the same for the input program and compiled program; only the stack matters. Also, it is not the case that stack always has a set of local variables represented in this way: the full match_states relation has 6 separate cases which say what the stack should be like when starting to execute a method, when executing the body, when returning from it (after the stack has been cleared), etc.
After defining the relation, we can finally state the correctness theorem.
Variable prog: StmtClinear.program.
Variable tprog: StmtStacked.program.
Hypothesis TRANSL: stacked_program prog = Success tprog.
Let ge := fst prog.
Let tge := fst tprog.
Theorem transf_step_correct:
forall s1 s2, Clabeled.Semantics.step me ge s1 s2 ->
forall s1' (MS: match_states s1 s1'),
exists s2', plus (Stacked.Semantics.step me cd) tge s1' s2' /\ match_states s2 s2'.
The variable/hypothesis says that we consider some program prog that the compiler phase has translated to a stacked program tprog without signaling an error. The theorem part can be represented as a square. It says that for any state s1 of the original program (the state includes storage, method arguments, the current location in the program, etc), if the program runs to a state s2 (which can includes e.g. new storage and return values), then if we start the compiled program in a suitably related state s1' it will also run without errors and reach a state s2' which is still related.
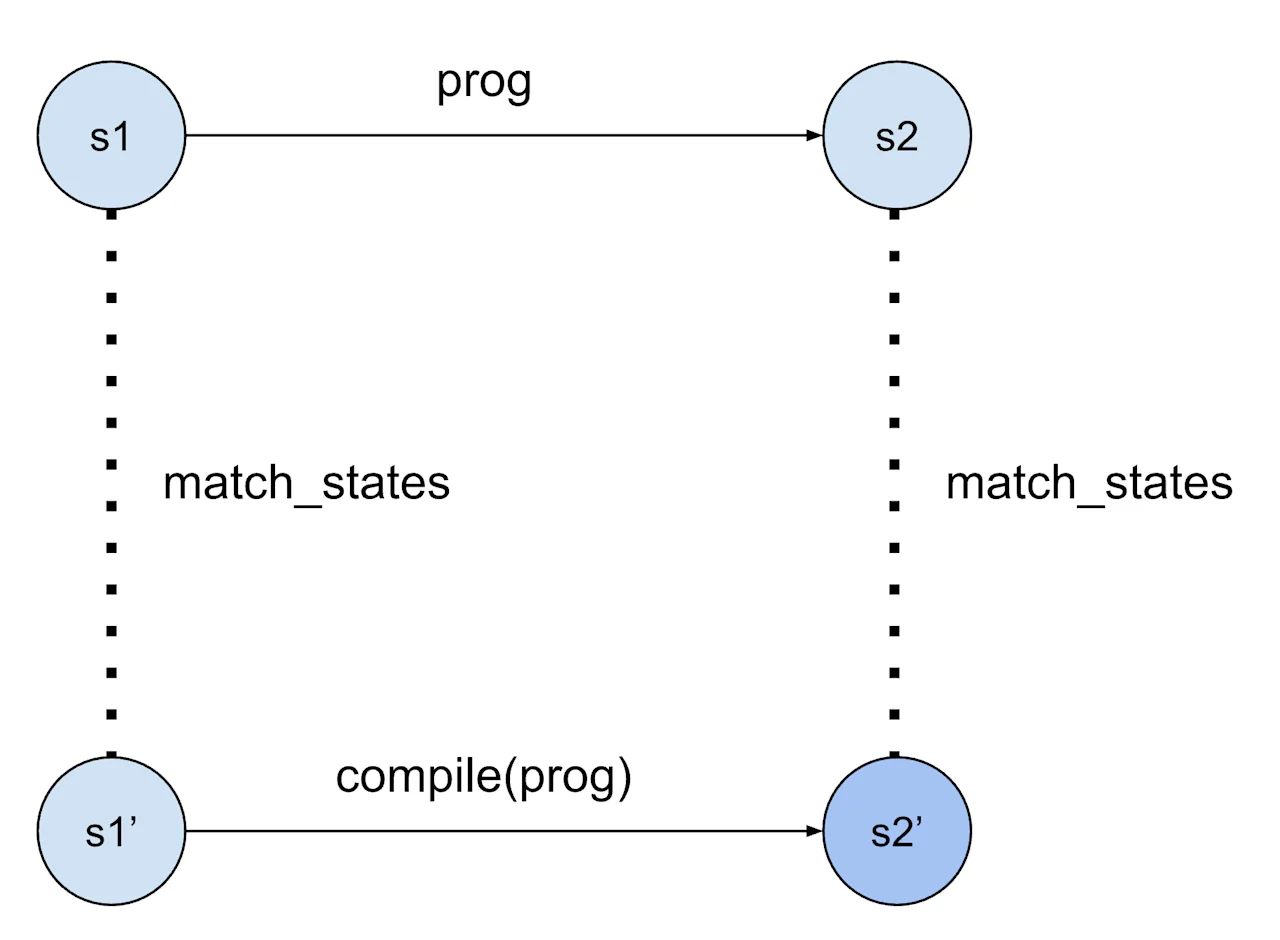
Paraphrased in English, this tells us that the compiled program returns the same value as the high-level program, has a storage which represents the same values that the high-level program stored, etc. The proof is fairly long: we consider each type of instruction that could be in the source program, see what the compiler translates it into, and then consider how the two instructions could execute and make sure that the resulting states still match.
Integrating Compilation and Formal Verification
The most obvious benefit of formal verification of compilers is to avoid errors in the generated bytecode, but they can also increase the confidence in formal verification of contracts.
The current state of the art in verifying Solidity programs presents a trade-off between ease of verification and trust in the verification tools. This is because if the verification is performed on a high-level representation of the program, a gap to the actual bytecode emerges. An unverified translation phase in the verification tooling could be even more error-prone than an unverified compiler, given that fewer people are using the tools, leading to less extensive testing.
In the early stages of formal verification for Ethereum, many projects actually verified the EVM bytecode directly. This approach was chosen as it is simpler to develop semantics for the EVM (which only comprises about 80 straightforward instructions, operating on a minimalistic stack and flat memory/storage) than for a full programming language, and one can be confident that the semantics accurately depict the actual execution. Thus, verifying a contract by compiling it and reasoning about the deployed bytecode in a proof assistant is both a quick way to initiate the process, and also a method to attain a highly trustworthy claim eventually.
However, this method does not scale beyond very small contracts. When the program is compiled, a single line of code can translate into a dozen stack operations, requiring the verification engineer to reconstruct the math formulas and temporary variables. Similarly, all data structure information is lost, and the verification engineer needs to track how raw bytes of storage correspond to the contract's state. This is manageable for small contracts (up to perhaps 100 lines of code) operating on simple data (e.g., numbers but not linked lists), but it is not cost-effective for larger code volumes.
More recently, working on a "model" of the code has become common practice. For instance, to verify a realistic DeFi protocol like Uniswap, verification engineers would initially craft a model program which mirrors the contract's operations. The model resembles the program's source code, but is written in the built-in programming language of the proof assistant rather than in Solidity. Following this, they verify the correctness properties of that model. For even higher assurance, one can also define a relationship between the possible states of the model and the corresponding states of the EVM machine for the compiled bytecode, and prove that the behavior of the compiled code aligns with the model. In practice, however, this step is frequently bypassed as it is seen to provide too little value for the investment.
This is where the verified compiler comes into play. As previously described, the DeepSEA correctness proof already establishes a relation between the high-level contract source code and the bytecode. This makes it feasible to verify the program at a high level, where the data is structured and arithmetic formulas are still recognizable. The DeepSEA compiler is integrated with the Coq proof assistant, enabling it to automatically generate a model that can be loaded into Coq. Additionally, we have the correctness proof indicating that the model aligns with the compiled bytecode, making the security properties of the contract as reliable as if they had been proved in Coq using just semantics for the bytecode.
As a demonstration of DeepSEA in a DeFi setting, we verified the swap method of a contract similar to Uniswap v2. Because DeepSEA currently works on its own programming language, we translated the Uniswap method line by line into the DeepSEA language. The DeepSEA compiler then automatically produces a model imported into Coq. This ensures that the model faithfully represents EVM semantics, so that the proofs are forced to take into account e.g. the rounding error of fix-point arithmetic. We prove a standard "non-decreasing k" property which shows that there are no bugs that drain funds, but we also take advantage of Coq's good support for mathematical reasoning to also prove theorems (previously only proved with pen and paper) about the cost of manipulating the price of the market.
Navigating the DeepSEA
DeepSEA was initially unveiled as a tech demo, but the ultimate aim is to evolve this technology to be beneficial for developers. This necessitates a full-featured programming language like Solidity, in contrast to the more minimalistic DeepSEA input language. Additionally, for contract verification to be of value, it should be integrated into a mature verification tool. A few years ago, the tool support for smart contract verification was generally lacking, making the construction of an end-to-end formally verified software development toolchain premature.
However, as formal verification gains prominence, the end-to-end vision becomes increasingly important. For instance, CertiK's internal tools for verifying Solidity contracts operate by initially translating them into a simpler "core" language, followed by the application of verification tools. This core language is only marginally more complex than the MiniC intermediate language embedded within DeepSEA. Looking ahead, it's envisioned that both compilers and verification tools will operate on a singular core language, with a formally verified compiler backend, ensuring that the security properties validated on the high-level representation remain intact even at the bytecode level.


