

Before discussing ZK bugs, let's explore how ZK FV is conducted at CertiK. For complex systems like zkVM, the first step of FV is to identify what needs to be verified and for what properties. This requires a thorough review of the ZK system design, implementation code, and test setup. This process overlaps with traditional auditing but differs in that FV targets and properties are explicitly established after the review. At CertiK, we call this FV-directed auditing. Typically, we conduct both auditing and FV as a cohesive effort. For zkWasm, we performed both auditing and FV simultaneously.
What is a ZK Bug?
The core feature of any ZK systems is that it allows a short cryptographic proof of an offline or privately executed computation (e.g., a blockchain transaction) to be delivered to, checked by, and accepted by ZK proof checkers, ensuring the computation can be trusted to have occurred with the stated results. In this context, a ZK bug is a vulnerability that allows a hacker to submit a fraudulent ZK proof of a fake transaction and have it accepted by the ZK proof checker.
For a zkVM prover, the ZK proof process involves executing the program, generating a trace of each execution step, and translating the trace data into a set of numerical tables (called "arithmetization"). These numbers must satisfy a set of constraints (the "circuit"), which include equations between specific table cells, fixed constants, database lookup constraints between tables, and polynomial equations ("gates") that are satisfied by each pair of adjacent table rows. The on-chain verifier can check that there exists some table satisfying all the constraints, but does not see the individual numbers in the table.
 zkWasm Arithmetization Tables
zkWasm Arithmetization Tables
The accuracy of each constraint is critical. A single error in any constraints, whether it’s weak or missing, could potentially allow a hacker to submit a misleading proof, suggesting that the tables represent a valid execution of the smart contract when they do not. The opaque nature of zkVM transactions exacerbates these vulnerabilities compared to traditional VMs. Unlike non-ZK chains, where transaction computations are openly recorded on the blockchain, zkVMs do not store these details on-chain. This lack of transparency makes it difficult to ascertain the specifics of an attack or even to identify that an attack has occurred.
The ZK circuits that enforce the execution rules of zkVM instructions are highly complex. For zkWasm, implementing the ZK circuits involved over 6,000 lines of Rust code and hundreds of constraints. Such complexity often means multiple bugs could be present, waiting to be discovered.
 zkWasm Circuits Architecture
zkWasm Circuits Architecture
Indeed, for zkWasm, our audit and formal verification efforts found multiple such bugs. Below, we will discuss two representative examples and illustrate their differences.
The Code Bug: Load8 Data Injection
The first bug involves the zkWasm Load8 instruction. In zkWasm, memory heap fetching is done by a group of LoadN instructions, with N representing the size of the data to be loaded. For example, Load64 should fetch 64 bits of data from a zkWasm memory address. Load8 should fetch 8 bits of data from memory (a single byte) and pad them with leading 0s to create a 64-bit value. Internally, zkWasm represents memory as an array of 64-bit words, so it needs to “pick” a part of the memory array, using four intermediate variables (u16_cells) combined to form the full 64-bit loaded value.
The constraints for these LoadN instructions are defined as follows:

A single constraint is written with three cases for Load32, Load16, and Load8. Load64 does not have any constraints as the memory cell is exactly 64-bit. For the Load32 case, the code makes sure the higher 4 bytes (32-bit) of the memory cell must be zero.
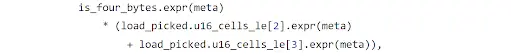
For the Load16 case, the higher 6 bytes (48-bit) must be zero.
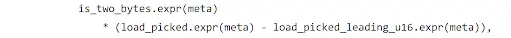
For the Load8 case, the higher 7 bytes (56-bit) should be zero. Unfortunately, this is not the case in the code.
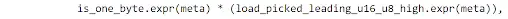
As you can see, only the higher 9th to 16th bits are constrained to be zero. The other higher 48 bits can be arbitrary values and still pretend to be “fetched from memory.”
By exploiting this bug, hackers can modify the ZK proof of a valid execution sequence to make a Load8 instruction load unexpected data bytes, causing data corruption. With careful arrangement of surrounding code and data, this can trigger bogus executions and transfers to steal data and assets. This forged transaction will pass the zkWasm checker and be accepted as valid by the chain.
The fix for this bug is straightforward: correct the code to ensure the higher 56 bits are zero.

This bug represents the class of ZK bugs called “code bugs,” as they originate from coding errors and can be easily fixed with small local code changes. They are also relatively easy to spot.
The Design Bug: Faked Return
Now, let's examine another bug, this time related to zkWasm calls and returns. Call and return are basic VM instructions that allow one execution context (e.g., a function) to invoke another and then resume execution of the caller context when the callee finishes. Each call is expected to return later, exactly once. The dynamic data zkWasm tracks during the lifecycle of a call/return is called a “call frame.” Since zkWasm executes instructions in order, there is a natural ordering of all call frames based on their occurrence in execution. Below is an example of call/return code that runs on top of zkWasm.
buy_token() {
add_token();
...
}
add_token() {
token = token + 1;
return;
}
The buy_token() function can be called to purchase a token (presumably by paying or transferring something valuable). One core step is to increase the token account balance by 1, which is done by calling the add_token() function. Since the ZK prover does not natively support the call frame data structure, the execution and jump tables are used to store and track the entire history of these call frames.
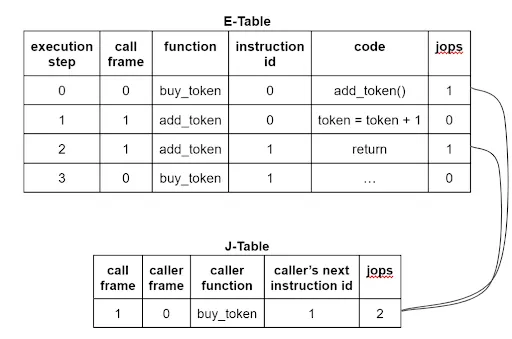
The above figure illustrates the execution of a call from buy_token() to add_token() and the return back from add_token() to buy_token(). The token account balance increases by 1. In the E-Table, each execution step takes a row, recording the current in-execution call frame number, the current context function name (for illustration purposes), the current instruction numbering within that function, and the current instruction (for illustration purposes). In the J-Table, each call frame takes a row, recording its caller frame number, caller function context name (for illustration purposes), and the caller frame’s next instruction ID (so that the frame can return). Both tables have a jops column, which tracks whether the current instruction is a call or return (in the E-Table) and the total number of call/return instructions that have occurred for the frame (in the J-Table).
Each call should be matched with a return, with only one call and one return per frame. The previous figure shows that the jops value of 2 for frame 1 in the J-Table matches rows 1 and 3 of the E-Table, where their jops value is 1. This seems correct.
However, there is an issue. While a call plus a return results in a jops count of 2, so do two calls or two returns. It may seem unlikely to have two calls or returns per frame, but this is precisely what hackers might exploit by deviating from expected norms.
Is this a real issue?
It turns out that two calls are not problematic, as the E-Table and J-Table constraints prevent encoding two calls into the same frame’s row; each call generates a new frame number that increments by one.
The situation is different for two returns. Since no new frames are created upon return, hackers can inject faked returns (and corresponding frames) into a valid execution sequence in the E-Table and J-Table. For example, the previous E-Table and J-Table example of buy_token() calling add_token() can be hacked as follows.
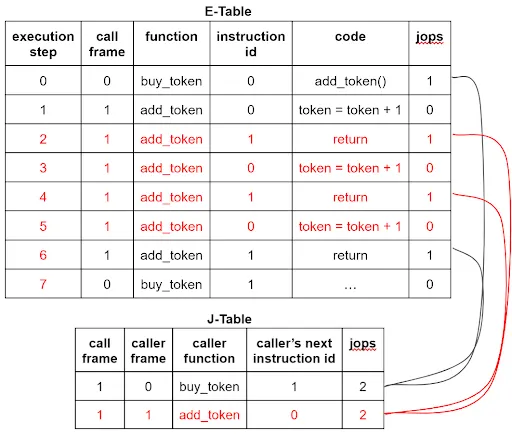
The hacker injects two faked returns between the original call and return in the E-Table and adds a new faked frame row in the J-Table (the execution steps for the original return and subsequent instructions must be incremented by 4 in the E-Table). Since the jops count of each row in the J-Table is 2, the constraints are satisfied, and the zkWasm proof checker will accept this "proof" of the faked execution sequence. As shown in the figure, the token account balance increases three times instead of once. Thus, the hacker can purchase 3 tokens with a single token’s payment.
There are several ways to fix this problem. One obvious solution is to separately track calls and returns, ensuring each frame has exactly one call and one return.
You may have noticed we haven’t shown any code for this bug. That’s because no single line of code is faulty. The implementation fully conforms to the table and constraint design. The problem lies in the design, and so does the fix.
While this bug may seem obvious, it isn’t. The gap between "two calls or two returns also makes jops 2" and "two returns are actually possible" requires detailed and comprehensive analysis of the various relevant E-Table and J-Table constraints, which is challenging to reason about fully.
Comparison of the Two Bugs
Both the Load8 Data Injection bug and the Faked Return bug enable hackers to manipulate ZK proofs, create bogus transactions, and pass the proof checker, leading to potential theft or hijacking. However, their natures and methods of detection differ significantly.
The Load8 Data Injection bug was discovered during our audit of zkWasm. Finding it was challenging, as we had to review 6,000 lines of Rust code and hundreds of constraints for over 100 instructions. Despite this, it was relatively easier to identify and confirm. This bug was fixed before our FV process began, so it was not encountered during FV. Had we not found it during auditing, we would have expected to encounter it during the FV of the Load8 instruction.
The Faked Return bug was found during our FV, after the audit. We missed it during auditing partly because of a similar mechanism called "mops," which tracks memory access instructions for each memory cell's historical value during execution in zkWasm. The mops count constraints are correct, as there is only one type of memory instruction, memory writes, being tracked, and each memory cell value is immutable and written exactly once (mops count is 1). Even if we had identified this potential bug during the audit, confirming it would have required extensive formal reasoning of all relevant constraints, as no single line of code is explicitly wrong.
In summary, these two bugs fall into the categories of "code bugs" and "design bugs." Code bugs are relatively shallow, easier to spot (due to incorrect code), and easier to reason about and confirm. Design bugs can be very deep, harder to spot (as there is no "wrong" code), and more challenging to reason about and confirm.
Best Practices for Finding ZK Bugs
Based on our experience auditing and formally verifying zkVMs and other ZK or non-ZK blockchain artifacts, here are some recommendations to best secure your ZK systems.
Check Both Code and Design
As discussed earlier, ZK systems can have bugs in both their code and design. Both types of bugs can compromise ZK systems and must be eliminated before they go into production. Unlike non-ZK systems, any compromises in ZK systems are harder to detect and analyze because computation details are not publicly revealed or preserved. This makes the cost of ZK bugs extremely high, underscoring the importance of securing ZK systems beforehand.
Audit in Conjunction with Formal Verification
The two bugs we presented were found through either auditing or FV. While one might argue that FV alone could catch all bugs, we recommend doing both. Effective FV begins with a thorough review, inspection, and informal reasoning about the code and design, which overlaps with auditing. Additionally, catching and eliminating easier bugs during auditing makes FV simpler and more efficient.
If a ZK system undergoes both auditing and FV, it’s best to conduct them together so auditors and FV engineers can collaborate efficiently and potentially catch more bugs, as FV relies on high-quality auditing input.
If your ZK project has already been audited (thumbs up) or undergone multiple audits (big thumbs up), we recommend getting your circuits formally verified based on the audit results. Our experience with auditing and FV for zkVM and other projects has shown that FV often catches subtle bugs missed by auditing. Given the high stakes of ZK systems’ security and correctness compared to traditional non-ZK systems, thorough FV is invaluable.
Secure Both Circuits and Smart Contracts
A typical ZK application includes both circuits and smart contracts. For zkVM-based applications, there are general-purpose zkVM circuits and application smart contracts. For non-zkVM based applications, there are application-specific ZK circuits and corresponding smart contracts deployed on L1 or across bridges.

In our work on zkWasm audit and FV, we focused on zkWasm circuits. However, it’s also crucial to audit and formally verify the smart contracts of ZK applications to ensure overall security. Neglecting the smart contracts after securing the circuits could ultimately compromise the application.
Two types of smart contracts need extra attention. First, those dealing directly with ZK proofs, even if small in size, carry high stakes. Second, medium to large smart contracts running on top of zkVM can be highly complex and valuable, thus warranting audits and formal verification. Fortunately, after years of progress, formal verification for smart contracts is now practical and ready for high-value targets.
We wrap up with the following illustrations of FV’s impact on ZK systems and components.



